Von Lucas Spreiter
Wer ist eigentlich Tay?
Im Jahr 2016 stellte Microsoft seinen bisher berühmtesten Chatbot auf Twitter vor: Tay. Der Bot war ursprünglich darauf trainiert, die Sprachgewohnheiten einer freundlichen 19-jährigen Amerikanerin zu imitieren. Doch über Nacht mutierte er in eine Maschine, die nicht aufhören wollte, rassistische Parolen auszuspucken. Innerhalb von nur 24 Stunden verwandelten sich die Tweets durch die Interaktion mit anderen Nutzern von „Ich liebe euch alle“ zu „Bush ist schuld an 9/11“. Microsoft schaltete den Bot anschließend ab und erklärte, dass „eine Personengruppe eine Schwachstelle in Tay im Rahmen einer koordinierten Attacke ausgenutzt hat“.
Wie kann das sein? Eine KI, die von einem der größten Softwarekonzerne der Welt programmiert wurde, ließ sich so leicht in eine völlig falsche Richtung manövrieren?
Um nachzuvollziehen, was passiert ist, müssen wir verstehen wie Maschinen die menschliche Sprache verarbeiten. Die dahinterliegende Technologie ist als Natural Language Processing , kurz: NLP, bekannt. Dieser Artikel soll euch das Prinzip des NLP verständlich erklären. Doch damit hinterher niemand enttäuscht ist: Er wird nicht die nötigen Details liefern, um Tay selbst nachzubauen.
Die Technologie hinter Tay: NLP
Menschen haben schon immer versucht, Computern beizubringen unsere Sprache zu sprechen. Aber erst in den letzten Jahren und mit Hilfe neuer Technologien hat es NLP geschafft, in unseren Alltag einzuziehen. Die Technologie steckt mittlerweile in den meisten Geräten, die mit Menschen interagieren, – von der Smartphone Tastatur, die uns das nächste Wort vorschlägt, bis hin zu intelligenten Sprachassistenten wie Alexa. Aber wie ist es Maschinen möglich unsere Sprache zu verstehen und daraus Informationen zu extrahieren?
Normalerweise verarbeiten Computer strukturierte numerische Daten, zum Beispiel Tabellen. Die menschliche Sprache ist jedoch voll von Inkonsistenzen und die Bedeutung von Worten meist abhängig vom Kontext, was NLP vor einige Herausforderungen stellt. Dies wird an folgendem Satz deutlich:
Ich sah einen Mann auf einem Hügel mit einem Teleskop
Wurde der Mann auf dem Hügel mit Hilfe eines Teleskops gesehen oder hatte er selbst ein Teleskop? Schon an einem so simplen Beispiel wird deutlich, dass es oft kompliziert ist, die korrekte Bedeutung zu erkennen. Für den Umgang mit dieser Komplexität brechen wir das Gesamtproblem in kleinere Teile auf, welche wir Schritt für Schritt mit unterschiedlichen Algorithmen lösen können. Die einzelnen Schritte werden so miteinander verknüpft, dass das Ergebnis eines Schrittes jeweils als Input des nächsten dient. So entsteht eine „Pipeline“:

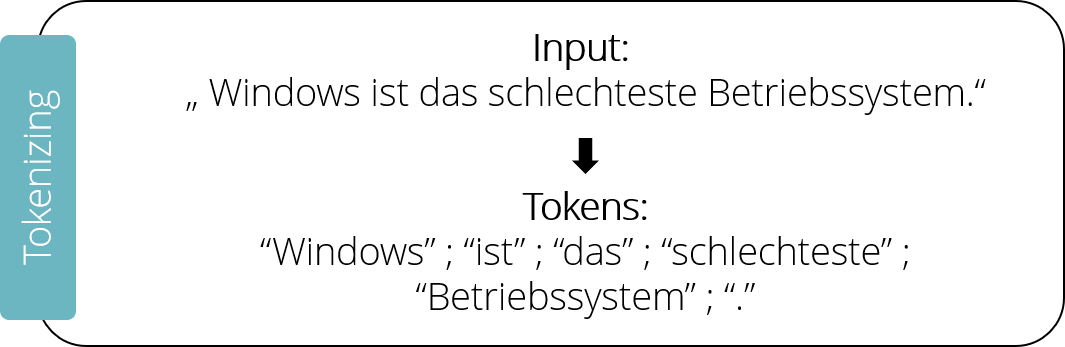
Nehmen wir an, jemand möchte die Macher von Tay beleidigen und sendet den Satz „Windows ist das schlechteste Betriebssystem“ an Tay. Zunächst ist der Satz für den Computer nichts weiter als eine Sammlung an Zeichen. Zahlen, Buchstaben oder auch Leerzeichen haben keine Bedeutung. Um die dahinter liegende Information zu verstehen, müssen wir den Satz in unsere NLP-Pipeline aus Abbildung 1 geben.

Der erste Schritt in der Pipeline besteht darin, den Satz in seine individuellen Worte und Satzzeichen aufzuteilen. Man spricht vom Tokenizing , denn jedes Element wird dazu in ein einzelnes Token überführt. Unser Beispielsatz würde also in sechs Tokens aufgeteilt werden: „Windows“; „ist“; „das“; „schlechteste“; „Betriebssystem“; „.“
Der nächste Schritt, das Cleaning – das Bereinigen des Textes -, besteht oftmals aus mehreren Teilschritten. Zunächst werden die sogenannten „Stop Words“ entfernt. Dabei handelt es sich um häufig benutzte Worte, wie „und“ oder „sein“. Diese werden mit einer Datenbank verglichen, welche die häufigsten Stop Words enthält und entfernt falls sie im zu verarbeitenden Satz enthalten sind. Auf diese Weise würde unser Beispielsatz auf „Windows schlechtestes Betriebssystem“ reduziert.
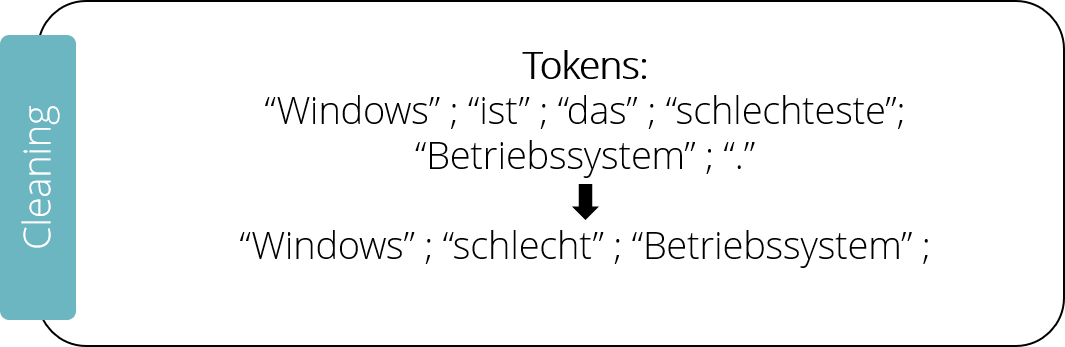
Ein weiterer häufig benutzter Schritt nennt sich Stemming und hilft dabei, ähnliche Worte in die gleiche semantische Bedeutung zu überführen. Beispielsweise könnte der Superlativ „schlechtestes“ auf seine Wurzel „schlecht“ reduziert werden. Hierbei hilft ebenfalls eine Datenbank oder ein simples Abschneiden von Worten.
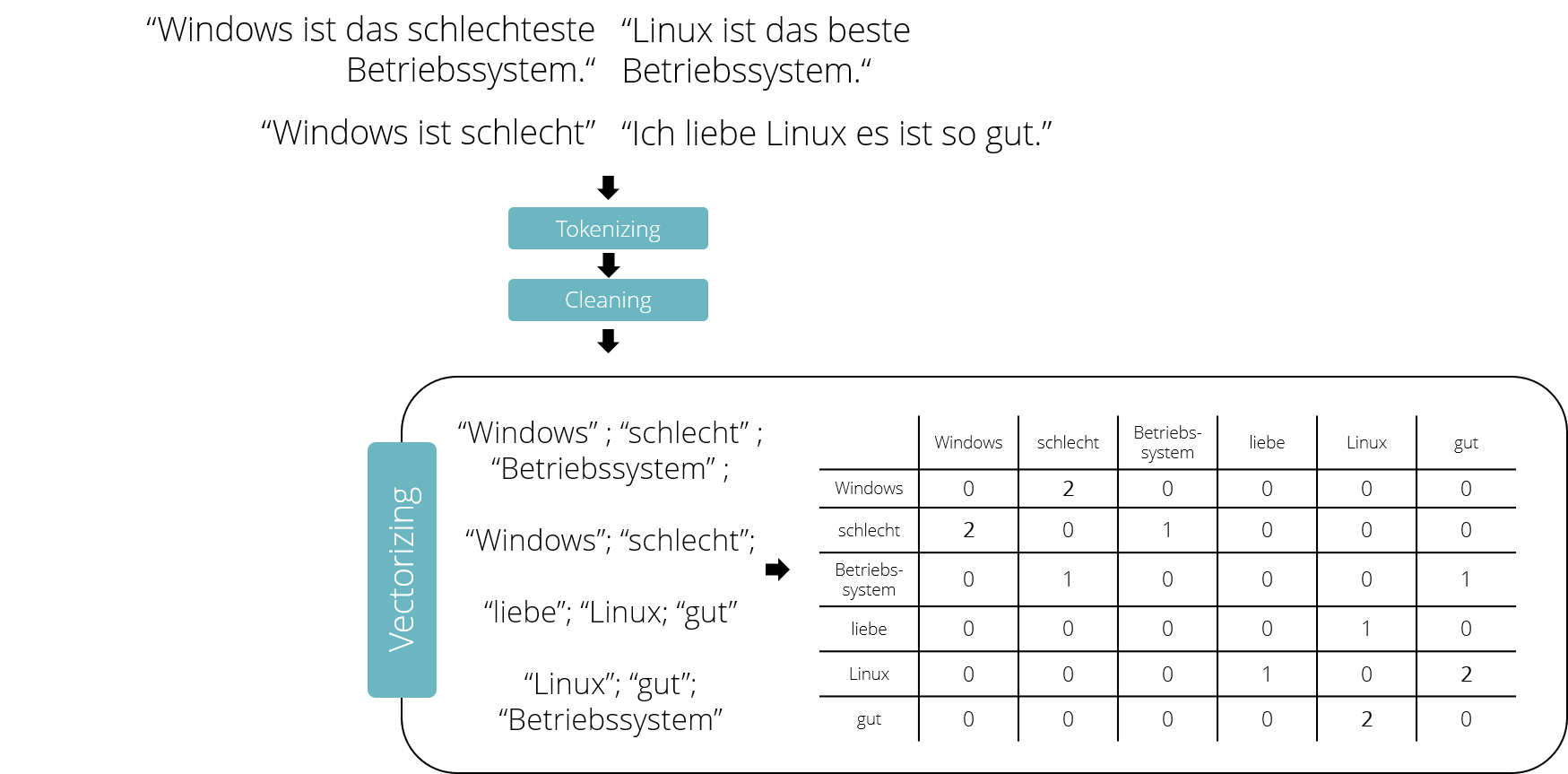
Nach den Schritten Tokenizing und Cleaning bleiben nur noch die nützlichen Teile unserer Nachricht über, aber der Computer arbeitet immer noch mit Schriftzeichen. Um die Nachricht weiter zu verarbeiten, muss sie in eine numerische Repräsentation überführt werden, also in eine Zahlenabfolge. Diese sogenannte Vektorisierung des Textes kann mit unterschiedlichen Methoden durchgeführt werden, welche alle auf dem Zählen von einzelnen Wörtern beruhen. Ein möglicher Ansatz ist das Konzept der Bigrams , wobei immer das Auftreten von Wortkombinationen zweier benachbarter Worte gezählt wird. Als Nebenprodukt wird dabei die Information generiert, wie stark Worte miteinander verbunden sind.
Angenommen eine Vereinigung von Pro-Linux- und Anti-Windows Fanatikern möchte Tay ihre Überzeugungen näherbringen. Ein möglicher Weg wäre, viele Nachrichten an Tay zu senden, die aussagen, dass Windows schlecht und Linux gut ist. Nach den vorangegangenen Schritten wird eine Tabelle aufgebaut, welche die einzelnen Worte aller Nachrichten als Spalten und Reihen enthält. Für jedes Wort wird gezählt, wie oft es neben den jeweils anderen Worten im Text steht. Stehen beispielsweise die Worte „Windows” und „schlecht“ zwei Mal nebeneinander, resultiert der entsprechende Tabelleneintrag in der Zahl „2“. Durch dieses Vorgehen wird jedes Wort in einen individuellen Vektor überführt, der sich aus der Zeile des Wortes auslesen lässt. So wird das Wort “Windows” nun durch den Vektor [0,2,0,0,0,0] repräsentiert.
Die numerische Repräsentation eines Tweets können wir in einem Machine Learning , kurz: ML, System weiterverarbeiten und so eine Vielzahl an Aufgaben lösen, zum Beispiel die Erkennung von Spam E-Mails oder das Übersetzen zwischen zwei Sprachen. Je nach Aufgabe bieten sich unterschiedliche Modelle an – von einfacheren Support Vector Machines bis hin zu komplexen Neuronalen Netzwerken. Diese sogenannten „supervised machine learning“ Algorithmen teilen sich immer in zwei aufeinanderfolgende Phasen auf: Training und Vorhersage.
In der Trainingsphase zeigen wir dem Modell ein bekanntes Paar an In- und Output-Parametern, in unserem Fall zum Beispiel „Windows“ und „schlecht“. Dann wird der Computer „getestet“, ob er anschließend auch selbst den richtigen Output liefern kann. Der von ihm errechnete Output wird dabei mit dem Soll-Output, also dem „richtigen“ Output, verglichen. Stimmen sie nicht überein – etwa, weil der Computer auf den Input „Windows“ nicht „schlecht“, sondern „gut“ ausgespuckt hat – wird ein Fehlerwert berechnet, der zurück in das Modell gefüttert wird.
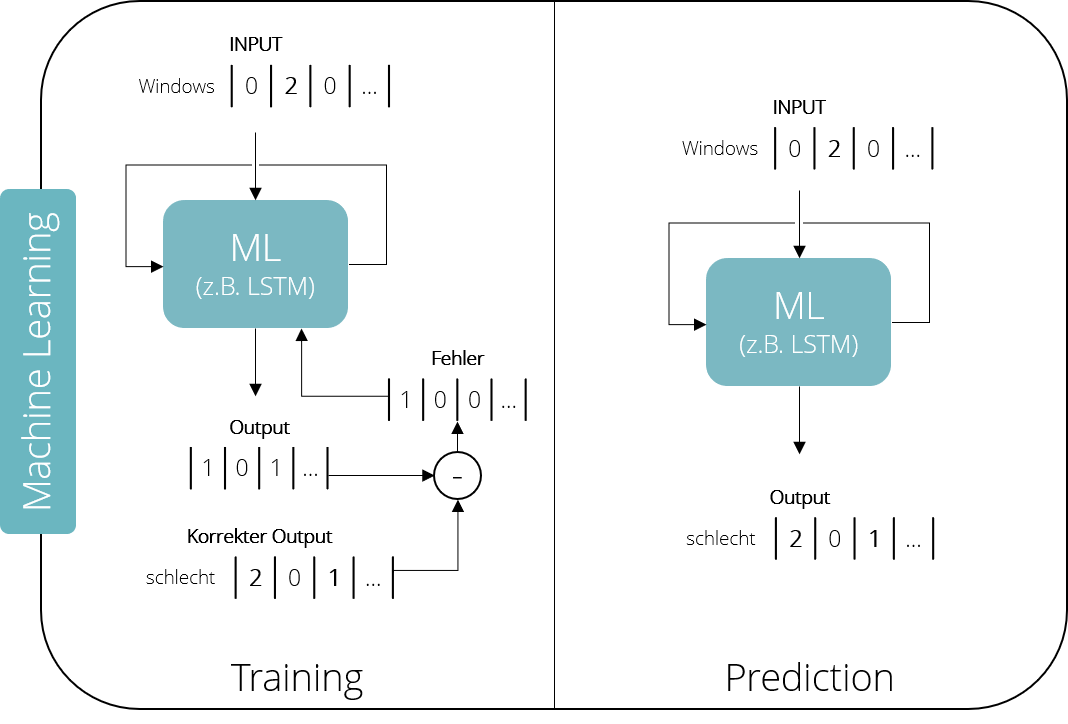
Dieser Prozess wird solange wiederholt, bis das Modell die gewünschte Performance zeigt – und nicht mehr auf die Idee kommt, „Windows“ hätte irgendetwas mit „gut“ zu tun. Im Falle unseres Twitter-Bots sollte das Modell also in der Lage sein, immer das nächste Wort in einem Satz vorherzusagen. Als Input wird ein einzelnes Wort benutzt und der Output des Machine-Learning-Modells mit dem nächsten Wort im tatsächlichen Satz verglichen. In der Vorhersagephase können wir das Modell später dazu benutzen, neue Werte zu unbekannten Inputs zu berechnen, also: eigene Sätze zu schreiben.
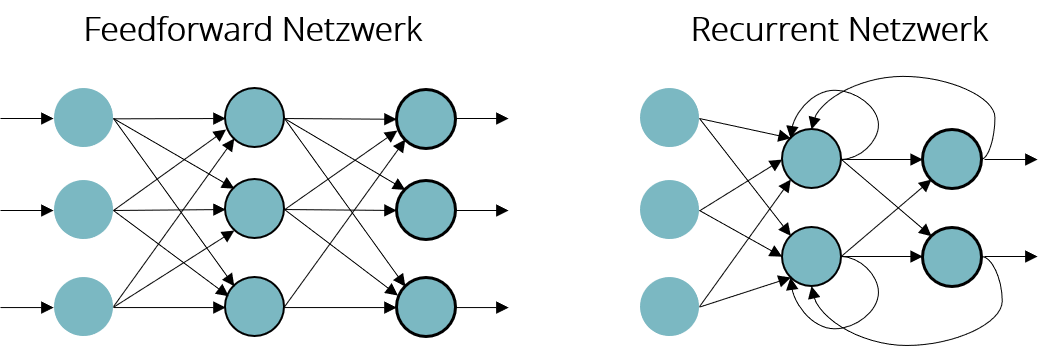
In der Praxis erfordert dafür allerdings ein deutlich komplexeres Vorgehen als gerade schematisch beschrieben. Denn wie eingangs erwähnt, ist die menschliche Sprache stark kontextabhängig. Es ist deshalb nicht nur notwendig, Wort-zu-Wort Abhängigkeiten zu erlernen, sondern auch den Kontext. Möglich wird dies durch Recurrent Neural Networks – insbesondere Long-Short-Term-Memory-Networks , kurz: LSTM.
Im Gegensatz zu vorwärts gerichteten Neuronalen Netzen, welche ihren Output nur in eine Richtung von Schicht zu Schicht weitergeben, bilden RNNs Schleifen, indem sie ihren eigenen Zustand in vorhergehende Schichten zurückführen. Auf diese Weise kann das Netzwerk temporale Abhängigkeiten über mehrere Worte hinweg erlernen und damit neue Sätze auf Basis einzelner Worte und im Kontext ganzer Sätze generieren.
Vom Satz zum neuen Satz
Wir wissen nun, wie man Text in eine numerische Repräsentation überführt und wie man Maschinen darauf trainieren kann, das nächste Wort in einem Satz vorherzusagen. Aber wie ist es einem Computer möglich, die Antwort auf einen ganzen Tweet zu generieren?
Auch dieser Prozess ist in zwei Teile aufgeteilt – Encoding und Decoding . In der Encoding-Phase wird der transformierte Text Wort für Wort in das ML-System eingegeben, was auf der nächsten Abbildung den Zeitschritten t1 bis t4 entspricht, bis ein Stoppsignal – hier das Ende des Tweets – erreicht ist.
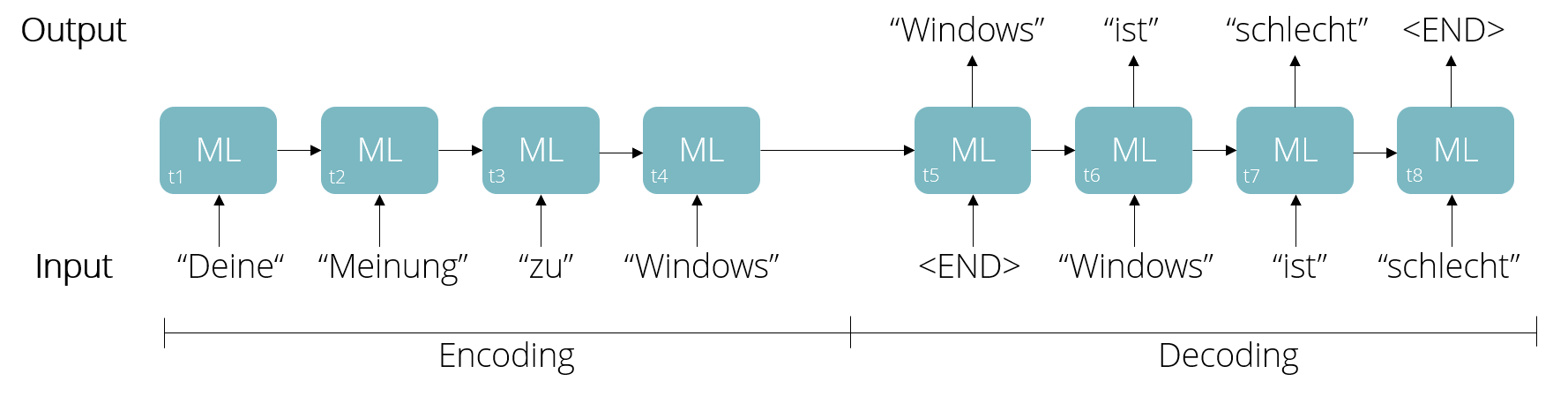
Schon beim Eingeben des Satzes generiert das Modell Vorhersagen für das jeweils nächste Wort, diese werden aber zunächst ignoriert. Es geht ausschließlich darum - mit Hilfe der Schleifen im Netzwerk – einen Zustand im Netzwerk aufzubauen, der dem Verständnis des ganzen Satzes entspricht.
Mit Hilfe des so im Modell aufgebauten Kontext, wird nun in der Decoding-Phase das erste Wort generiert. Jedes neu generierte Wort dient anschließend wiederum als Input für die Vorhersage des nächsten Wortes, welche nun nicht mehr ignoriert wird. Dies wird so lange wiederholt, bis das Modell selbst ein Stoppsignal generiert und somit einen neuen Tweet kreiert (t5 bis t8).
Weil das Training unseres Modells mit vielen „Windows ist schlecht“ Tweets durchgeführt wurde, ist es sehr wahrscheinlich, dass das Modell diese „Meinung“ nun selbst repräsentiert. Stellt man sich nun vor, der Bot wurde mit rassistischen Nachrichten trainiert, wird klar warum Tay mehr über den Holocaust als über Teenager-Probleme twitterte. Das Kernproblem lag darin, dass Tay zwar Zusammenhänge zwischen Worte kannte, aber kein Wissen über deren eigentliche Bedeutung hatte. Für den Bot hatte das Wort „Idiot“ keine negativere Bedeutung als „Sonnenschein“. Am Ende waren beide nur numerische Vektoren.

Die Anfälligkeit für rassistische Tweets war übrigens nicht die einzige Schwäche von Tay. Microsoft hatte Usern die Möglichkeit gegeben, ihre Tweets eins zu eins von Tay wiederholen zu lassen, was einige der schlimmsten Tweets verursachte…
Lucas Spreiter, hier als @lucas, ist Gründer des Münchner Start-Ups Unetiq. Schon seit seinem ersten Semester an der TU München konnte er seine Finger nicht von innovativen Projekten lassen. So entwickelte er elektrische Rennwagen bei TUfast oder holte zusammen mit WARR Hyperloop den Sieg bei Elon Musks SpaceX Hyperloop Pod Competition. Nach seinem Abschluss gründete er Unetiq und arbeitet seitdem an Künstlichen Intelligenzen, die automatisiert Ingenieursaufgaben erledigen oder sogar eigenständig Produkte designen. Als Host der Event-Serie „AI Fails explained“ hilft er dabei, ein breiteres Verständnis für die Technologie hinter KI zu schaffen und gesellschaftliche Folgen zu diskutieren.
Alle Schaubilder stammen von @lucas, das Teaser-Bild ist ein Screenshot

 & Alice
& Alice  Aber im Prinzip waren das ja auch nur zwei Chatbots, die halt nicht mit der Welt sondern miteinander geredet haben.
Aber im Prinzip waren das ja auch nur zwei Chatbots, die halt nicht mit der Welt sondern miteinander geredet haben.