Mit SuperMUC-NG Phase 2 rücken Supercomputing und Künstliche Intelligenz am LRZ noch enger zusammen: Die darin verbauten Graphics Processing Units (GPU) im neuen System begünstigen Methoden der Künstlichen Intelligenz, die wiederum klassische Simulationen bereichern, beschleunigen oder ergänzen diese. Erste Erfahrungen aus Natur- und Umweltwissenschaften.

Forschen und Simulieren: Künstliche Intelligenz erweitert das Methodenset in der Wissenschaft. Foto: Adobe
Deutliche, höher aufgelöste Bilder stammen heute nicht immer aus Kameras, Mikroskopen und anderen Aufnahmegeräten. Sie können auch das Ergebnis von bloßer Datenverarbeitung sein. Das zeigt sich am Beispiel des World Settlement Footprint (WSF), eine Reihe von Datensätzen, die das Deutsche Zentrum für Luft- und Raumfahrt (DLR) aus Radar- und Multispektralbildern von Satelliten erstellt. Diese werden aus frei verfügbaren Satelliten-Bildern berechnet und zeigen, wie sich weltweit die Siedlungsflächen seit 1985 verändert haben und weiterentwickeln. Durch Methoden Künstlicher Intelligenz (KI) wird deren räumliche Auflösung von 10 bis 30 Metern auf unter 10 Meter verbessert. Dabei werden Referenzbilder von kommerziellen Anbietern mit sehr hoher Auflösung von einem Meter oder feiner eingesetzt. „Um den Settlement-Footprint zu optimieren und mit mehr Informationen anzureichern, ist die Superresolution mega-interessant", erläutert Dr. Mattia Marconcini vom DLR. "Sie ist allerdings noch schwer hinzubekommen.“ Auf schärferen, detaillierteren Bildern ließen sich möglicherweise Wirtschafts- von Wohngebäuden unterscheiden, vielleicht sogar die Entwicklungen einzelner Stadtviertel nachvollziehen. Noch ist das Zukunftsmusik, aber den dazu notwendigen Zoomeffekt wird KI einmal aus vorhandenen Bilddaten simulieren können.
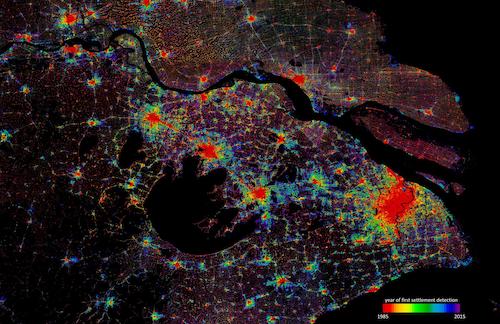
Der World Settlement Footprint zeigt die Entwicklung von Siedlungsflächen seit 1985 bis heute: Hier sind die unterschiedlichen Phasen von Shanghai zu sehen. Foto: DLR
GPU bringen neue Impulse für die Simulation
Klassische Simulationsverfahren und KI-Modelle rücken näher zusammen. In der Forschung wie auch technisch: SuperMUC-Phase 2 (SNG-2) startet demnächst in den Betrieb und wurde mit 960 Graphics Processing Units (GPU) von Intel (Ponte Vecchio) ausgerüstet. GPU sind auf die Verarbeitung großer Volumen aus Bild- und Grafikdaten spezialisiert, sie beschleunigen im High Performance Computing (HPC) Berechnungen und eignen sich gleichzeitig für KI-Verfahren: „HPC und KI werden von Beschleunigern angetrieben, insbesondere von GPU“, sagt Dieter Kranzlmüller, Leiter des Leibniz-Rechenzentrums (LRZ) und Informatik-Professor an der LMU. „Wir erweitern SuperMUC-NG Phase 2 mit KI-Fähigkeiten, um neue Erkenntnisse und Entdeckungen zu ermöglichen. Im Zusammenspiel von Simulationen und KI liegt neues Wissen.“ Bislang werden klassische Simulationen noch oft an Supercomputern berechnet und die Resultate an speziellen KI-Clustern ausgewertet, um mit diesen Erkenntnissen wiederum die Modellierung zu optimieren. Jetzt sind klassische Modellierung und KI auf einem Rechner möglich, um beide Methoden gemeinsam und reibungslos nutzen zu können, braucht es jedoch neue Prozesse und Workloads, die das LRZ nun mit Forschenden an SNG-2 erarbeiten wird.

SuperMUC-NG, Phase 2: Das Ergänzungssystem wurde mit 960 GPU ausgestattet. Foto: LRZ
„Die Verbindung zwischen physikalisch basierten Simulationen und KI ist zurzeit eines der heißesten Themen auf Kongressen und Konferenzen“, beobachtet Prof. Ralf Ludwig vom Department für Geografie und komplexe Umweltsysteme der Ludwig-Maximilians-Universität München (LMU). Projekte, die mit KI-Methoden arbeiten, stoßen nicht nur in den Umwelt- und Lebenswissenschaften auf höchstes Interesse. Alle Fachrichtungen experimentieren bereits mit KI-Methoden zur Analyse von Daten und deren Integration in bestehende Modellierungsverfahren. „Die Umweltwissenschaften verfügen über enorme Datenströme, etwa aus der Fernerkundung“, nennt Ludwig einen Grund, der nicht nur für sein Fach gilt. „Wissenschaftliche Arbeitsgruppen stoßen bei der Auswertbarkeit inzwischen an Grenzen.“ Von besonderem Interesse bei der Methoden-Kombination sind Surrogat-, Ersatz- oder Metamodelle sowie Emulatoren, also Annäherungen an eine mathematisch-physikalisch berechnete Modellierung, die mit Hilfe von Verfahren wie Mustererkennung und Machine Learning entstehen und Messwerte sowie andere digitale Informationen aus der Realität verarbeiten. Das Surrogatmodell kann
- mit den Werten und Ergebnissen aus klassischen Simulationen trainiert werden und danach helfen, deren Parameter zu variieren und in kürzerer Zeit mehr Szenarien zu berechnen,
- rechenintensive Teile einer Simulation ersetzen,
- die klassische Simulation durch Daten über naturwissenschaftliche Phänomene ergänzen, die mit Formeln und Gleichungen schwer oder – wenn überhaupt – nur näherungsweise und mit höchstem Aufwand zu berechnen sind.
Surrogatmodell und andere KI-Methoden
„Das Surrogatmodell ist ein Ersatz für ein physikalisches oder mathematisches Modell, auch wenn der Input von Trainingsdaten nicht zwingend aus einer Simulation kommen muss“, erklärt der Mathematiker Dr. Felix Dietrich vom Lehrstuhl Wissenschaftliches Rechnen der Technischen Universität München (TUM). Er erforscht als Leiter einer Emmy-Noether-Forschungsgruppe datengetriebene Surrogatmodelle, präzisiert deren Aufbau und das Training mit Daten. „Ersatzmodelle werden nicht entwickelt, um die Physikforschung voranzutreiben, sondern um schneller und genauer zu rechnen, sie sind eine Methode, Modelle mit viel mehr Parametern zu nutzen.“ Noch ist die Skepsis bei deren Einsatz in der Forschung hoch. KI liefert Ergebnisse, die zwar stimmig, aber oft nicht nachvollziehbar sind. KI-Modelle gelten auch als Blackbox, in die Dietrich und seine Arbeitsgruppe Licht bringen wollen.

Die Arbeitsweisen von KI-Modellen und -Verfahren müssen erforscht werden, damit die Ergebnisse einschätzbar, zuverlässig sind und vor allem keine Vorurteile enthalten. Foto Adobe
„Aufgrund der Effizienz KI-basierter Modelle besteht das Risiko, dass Forschende die physikalisch basierten Simulationen schneller über Bord werfen“, gibt Umweltwissenschaftler Ludwig zu bedenken. So gesehen führt der Name „Ersatz“- oder „Surrogatmodell“ zu Missverständnissen, diese Modelle können und sollten die physikalisch-mathematische Berechnung von natürlichen Phänomenen oder Systemen gerade nicht ersetzen: „Das Ersatzmodell wird zum Selbstzweck, wenn dabei die Modellierung verloren geht“, stellt Modell-Forscher Dietrich klar. „Dadurch geht deren Hauptzweck, das Verständnis, verloren. Ziel der Wissenschaft ist es ja nicht, Modelle zu bauen, sondern die Welt zu verstehen, und der Erkenntnis nutzt es nichts, wenn die Maschine oder der Computer etwas gelernt hat.“ Zu erwarten ist indes, dass Surrogatmodelle und andere KI-Methoden die klassische Simulation nicht verdrängen, sondern diese im Gegenteil bereichern, erweitern, ausdifferenzieren, auch veredeln. Mischformen für die Modellierung werden entstehen und mit ihnen weitere Methoden. Folgende Szenarien werden bereits erprobt:
Szenario 1: Mit KI Simulationsergebnisse auswerten und ausdifferenzieren
Klassische Simulationen basieren auf Naturgesetzen, die mathematisch und in der Regel mit Hilfe von Differenzialgleichungen formuliert werden können. Die Gültigkeit der Ergebnisse wird durch Beobachtungen in Natur und Realität oder durch Experimente nachgewiesen. Simulationen sind präzise, benötigen aber viel Zeit und Rechenkraft auch für die Auswertung der Resultate. Die Forschungsgruppe um Ludwig simulierte für das deutsch-kanadische Projekt „Climate Change and Extrem Events“ (ClimEx) 2018 die Klimaentwicklung Bayerns für einen Zeitraum von 150 Jahren. Für jedes Jahr wurden aus Klima- und Wasserwirtschaftsdaten 50 Szenarien berechnet, um die Folgen von Extrem-Wetterevents zu beurteilen und Prognosen für die Zukunft abzuleiten. Zur Berechnung der 7500 Modelljahre benötigte der Supercomputer des LRZ insgesamt knapp 90 Millionen Kernstunden, danach lag ein Datensatz von mehr als 500 Terabyte vor. Zum Vergleich: Ein Terabyte entspricht in etwa dem Fassungsvermögen von knapp 1500 CD-Roms.
Aus diesem Datenschatz können Forschende noch immer neues Wissen ziehen, das ClimEx-Team wertete ihn auch mit KI-Methoden aus: „Mit Hilfe von Mustererkennung klassifizierten wir darin zum Beispiel Muster in Luftdruck-Konstellationen, die Extremwetter wie Starkregen oder Dürren begünstigen können“, berichtet Ludwig. Diese wiederum halfen, die Parameter der Simulationen einzugrenzen und Prognosen zu präzisieren. Inzwischen ist die zweite Phase des ClimEx-Projektes gestartet, die Modelle werden nun um Kriterien rund um den Wandel in der Landnutzung erweitert, um das Auftreten von Trockenheit zu erklären. „Mit Hilfe von KI-Methoden identifizieren wir nun räumliche Muster, mit denen wir die Wahrscheinlichkeit für das Auftreten von Dürren und Hitzeperioden berechnen und daraus ebenfalls Vorhersagen ableiten können“, so Ludwig. „Wir verfügen über ein gutes physikalisches Verständnis der zugrunde liegenden Prozesse, können KI nutzbringend einsetzen, um deren räumliche und zeitliche Muster statistisch robust und probabilistisch zu erfassen oder um neue Muster aufzudecken.“
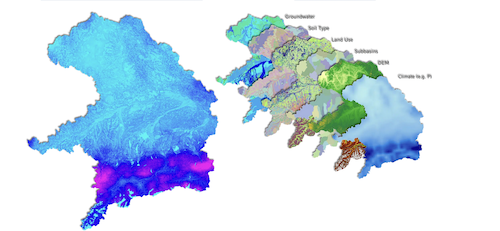
Climex I und II: Die Projekte spüren dem Klimawandel nach, zeigen die Folgen von Starkregen in Bayern sowie in Ontario und spüren nun auch den Ursachen von Trockenheit und Dürren nach. Foto: ClimEx Projekt
Szenario 2: Aus Simulationen Trainingsdaten für KI gewinnen
KI unterstützt nicht nur die Auswertung, sie kann außerdem mit den Ausgabedaten von klassischen Simulationen trainiert werden. So entstehen Surrogatmodelle: „Simulationen sind zwar präzise, aber auch extrem teuer und langsam“, erläutert Prof. Volker Springel, Direktor des Max-Planck-Instituts für Astrophysik. „KI lernt, reproduziert und verallgemeinert, was sie aus Trainingsdaten kennt.“ Und mit diesen Fähigkeiten soll sie nun physikalische oder mathematische Simulationen bereichern: „KI-Methoden können das Maximum aus den Daten herausholen, das allein ist schon eine wichtige Hilfe“, meint Springel. „Eine andere liegt in der so genannten Inferenz, also darin, wie man aus Beobachtungsdaten die grundlegenden Größen herausfiltert, die interessieren.“ Als Beispiele nennt der Astrophysiker die Dichte des Universums, die Hubble-Konstante und andere kosmologische Parameter. Mit einer internationalen Arbeitsgruppe hat der Astrophysiker gerade MillenniumTNG vorgelegt, eine viel beachtete Serie großvolumiger Simulationen über das Universum. Diese beschreibt eine Region von zehn Milliarden Lichtjahren, berechnet darin die Entstehung von Galaxien und Sternen, außerdem Prozesse wie Supernova-Explosionen und das Wachstum von Schwarzen Löchern. Erstmals wurden dabei auch die massereichen Neutrinos einbezogen. Die Datensätze umfassen immerhin drei Petabyte oder 3000 Terabyte an Informationen.
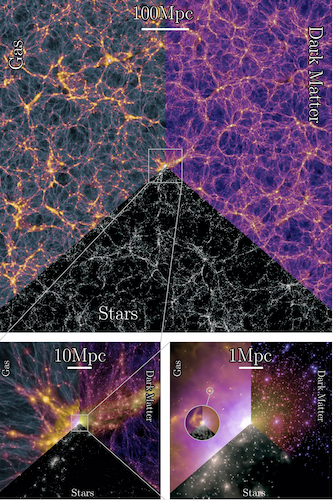
Millennium TNG: Das Bild zeigt Bilder aus der Simulation, die Zoom-Stufen verdeutlichen die Größe der Simulationsgröße von 2400 Millionen Lichtjahren (oben mittig) bis zur einer einzelnen Galaxie (rechts unten). Foto: MPG
Auch sie werden Astrophysiker:innen lange beschäftigen – und ebenso KI. Bei der Auswertung setzen Springel und seine Kolleg:innen neben Mustererkennung auch auf das Training mit Daten: „KI-Systeme können Voraussagen extrem beschleunigen, indem man auf der Basis von einzelnen Punkten, die präzise simuliert wurden und zwischen denen man interpoliert, sogenannte Emulatoren trainiert.“ Diese wiederum bilden dann die Funktionsweisen der Simulation nach, indem sie Berechnungen durch Beobachtungsdaten und Messwerte ersetzen und auf diese Art besonders schnelle Aussagen ermöglichen oder Hypothesen bestätigen helfen. Sie ersetzen damit einen Teil der rechenintensiven Modellierung: „Ein methodischer Durchbruch“, sagt Springel. Dieser beschleunigt das Simulieren am Computer und erweitert den wissenschaftlichen Wert einzelner Modellierungen, wie erste Paper bereits zeigen.
Szenario 3: Mit Surrogatmodellen Simulationen variieren
Überlässt die Astrophysik rechenintensive Teile großvolumiger Simulationen KI-Systemen, entwickeln andere Fachdisziplinen spezielle KI-Modelle für das Training mit Simulationsdaten, um mit weniger Aufwand und Zeit Varianten zu erstellen. „KI hilft, mehrere Szenarien schneller zu modellieren. Wir können damit aus bestehenden Simulationen des WSF in kurzer Zeit und mit veränderten Parametern weitere Szenarien ableiten“, sagt DLR-Forscher Mattia Marconcini. „Die Ergebnisse werden dadurch seriöser.“ Führen Modellierungen trotz veränderter Attribute zu vergleichbaren Ergebnissen, stützt das die Plausibilität der Originalsimulation.
Damit aber nicht genug: Bislang werden die Veränderungen der Siedlungsflächen jahresweise dokumentiert und wird der WSF etwa alle zwei Jahre neu modelliert und dabei mit grundlegenden Verbesserungen in der Simulation ausgestattet. Als Open-Source-Tool unterstützt der WSF auch andere Projekte. Das DLR-Team will mit Hilfe von Surrogatmodellen kurzfristige Veränderungen von Siedlungen und Mega-Cities abbilden und dazu den WSF aus aktualisierten Satellitendaten halb- oder gar vierteljährlich neu berechnen. „Ohne KI wäre das nicht möglich“, meint Marconcini. Mit Hilfe der Surrogatmodelle können neue Daten schneller integriert und berechnet werden. Der WSF kann dadurch nicht nur in kürzeren Abständen generiert, sondern inhaltlich durch weitere Informationen zur Entwicklung der Städte erweitert werden. So lassen sich mit dem WSF 3D schon die Höhen von Gebäuden schätzen. KI ermöglicht zwar die Darstellung von kurzfristigen Entwicklungsschritten, doch das Basismodell optimieren, kann das mit Daten trainierte KI-System nicht.

Der Settlement Footprint wird inzwischen auch in 3D erstellt: KI ergänzt Daten und ermöglicht die Schätzung von Gebäudehöhen. Foto: DLR
Szenario 4: Mit KI-Modellen klassische Berechnungen ergänzen und veredeln
Schließlich gibt es in der Natur noch Phänomene und Systeme zu entdecken, die sich mit klassischen Rechenmethoden nur unzureichend beschreiben lassen. Umweltforscher Ralf Ludwig verweist als Beispiele auf gekoppelte Systeme, in denen natürliche Prozesse etwa durch menschliches Handeln geprägt werden, ohne dass dafür klare Regeln ersichtlich sind. Beispiele sind Gewässertemperaturen oder Wasserqualitäten im Umfeld von Unternehmen und Staudämmen oder auch die Temperaturunterschiede über Acker- und Waldböden. Solche Aspekte können Standardsimulationen nicht abbilden, sie wären nur mit höchstem Mess- und Datenaufwand zu berechnen. „In diesen Fällen ist es effizienter, die prozessbasierte Simulation durch KI zu ergänzen und aus Observations- und Messdaten heraus Zusammenhänge zu erschließen.“
Mit dem Wissen aus Simulationen und mit Hilfe von Messwerten, Wetter- und Klimadaten werden Surrogatmodelle trainiert, die Lücken füllen, Modellrechnungen erweitern oder durch höhere Genauigkeit veredeln. Ludwig spricht in diesem Zusammenhang von einer Künstlichen Intelligenz, die “explainable“ oder „physics aware“ sein sollte, deren Resultate sich mit klassischen Methoden vergleichen lassen. Ein Verfahren, das auch in Chemie und Physik das Verständnis von Zusammenhängen verbessern könnte – etwa in den Molekularwissenschaften und in der Teilchenphysik: „Im Prinzip ist das Modell, das ich aus riesengroßen Datenmengen entwickle, nichts anderes als eine Zusammenfassung von Daten, und über das Ersatzmodell kann ich diese in eine Simulation hereinbringen“, stellt der Numeriker Dietrich fest. „KI ist nicht nebulös, ihre Algorithmen funktionieren mit Daten über ein System. Der Unterschied zu mathematischen Modellen: Sammeln wir mehr Daten, verändert sich in einem mathematischen Modell nichts, aber ein Mehr an Training könnte das KI-Modell ändern.“ Was wiederum Verunsicherung nach sich ziehen kann und daher erklärt werden muss. Aber solche Modelle ergänzen Simulationen um die Beschreibung von Phänomenen, für die es nur empirische Daten gibt.
Neue Workloads für HPC und Simulation
Surrogatmodelle und KI-Methoden ersetzen Rechenkraft, erweitern physikalisch-mathematische Simulationen durch Beobachtungsdaten und sorgen für mehr Genauigkeit in klassischen Modellierungen. Wo ihr Einsatz sinnvoll ist und wie KI-Modelle aufzubauen sind, das wird jetzt intensiv erkundet. Ludwig setzt auf ein Neben- und Miteinander der Methoden. „Dort, wo wir ein gutes physikalisches Verständnis und die Plausibilität brauchen, werden wir prozessbasierte Ansätze und Simulationen verwenden, und in den Bereichen, in denen wir berechnungstechnisch viel Zeit verbrennen oder die Datenlage noch nicht ausreichend kennen, werden wir Ansätze aus der KI einfügen, um insgesamt ein robustes Modellergebnis zu erzeugen.“ Dieses Nebeneinander wird mittelfristig die Forschungsteams verändern: Waren beim Erstellen von Modellen, beim Implementieren auf HPC-Systeme und beim Ausführen bislang Fachdisziplin(en), Numerik/Mathematik sowie Informatik beteiligt, ist nun noch die Expertise von Datenwissenschaftler:innen gefragt. Nicht mehr die Computertechnik oder die nötigen Formel- und Datensets, sondern das gegenseitige Verständnis wird daher zur größten Herausforderung beim Simulieren werden.
Am LMU-Department Physische Geografie und komplexe Umweltsysteme bauen sie schon vor: Gesucht werden dort Spezialist:innen für die Wissenschaftskommunikation, die Fachsprachen übersetzen und zwischen unterschiedlichen Bergrifflichkeiten und Anforderungen vermitteln. „KI“, fordert Ludwig, „darf für Forschende keine Blackbox bleiben, wenn wir nicht selbst im Detail in die Modelle hineinschauen können, dann müssen wir mit zuverlässigen, kompetenten Partner:innen zusammenarbeiten, die sehr genau wissen, wie sie diese Systeme zu bedienen haben.“ (S. Vieser/LRZ)